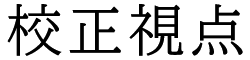
![GoogleドキュメントのOCRの精度がスゴい!無料のおすすめ文字読み取り機能[画像・PDF・手書き文字で検証]](https://kousei.club/wp-content/uploads/2022/01/Google-Document-OCR.jpg)
![]()
目 次
GoogleドキュメントのOCRの精度がスゴい[画像・PDF・手書きで検証]
OCR(Optical Character Recognition/Reader)とは、文字の読み取り機能のことを言います。紙に印字された文字や手書き文字をテキスト化するのに役立ちます。現在では、スマホからでも文字を読み取ることができるので便利さを実感されている方も多いはずです。
ここで紹介するGoogleドキュメントにもOCRと同様の機能が備わっています。グーグルアカウントさえ持っていれば誰でも使用できます。面倒なインストールも不要です。
Googleドキュメントは、本来文書作成に使用するツールですが、使い方によっては画像やPDFの文字情報の読み取りが可能となります。
この記事では、文字の読み取り方法をはじめ、画像やPDF、手書き文字などでの読み取り精度の検証を紹介しています。
あくまで文字情報のみを抜き出す目的での使用です。改行や太字、文字色など体裁の設定までは読み取ることができません。
また、グラフや表組みの設定なども活かされません。これは有料版でも厳しいため、現段階では無料版に期待するのはかなり難しい状況です。
1. 文字情報の読み取り手順
手順は簡単です。1分もかかりません。
画像もPDFもすべて同じ手順です。
1. グーグルのTOPページを開きます。
❶ 右上の【Googleアプリ】をクリックします。
❷ その中の【ドライブ】をクリックして開きます。
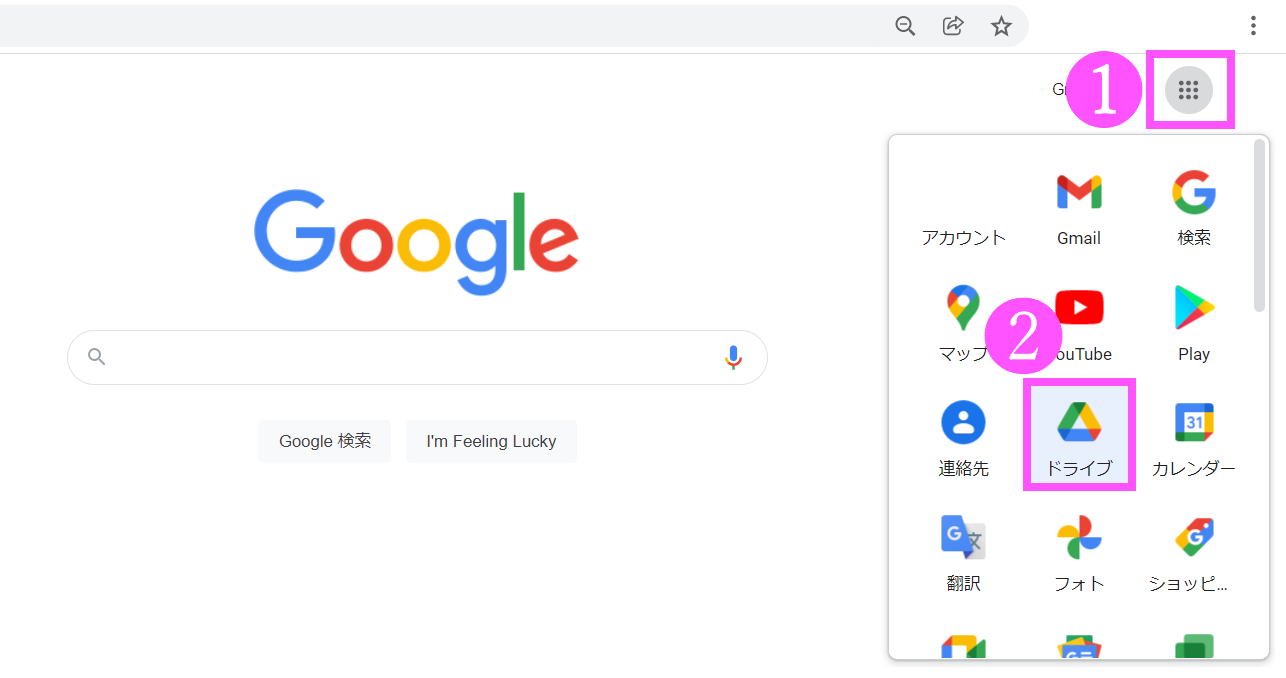
2.【ドライブ】を開いた画面です。
マイドライブの画面に、文字情報を抜き出したいファイルをドラッグします。
ここでは、「テスト1」というPDFファイルをドラッグしています。
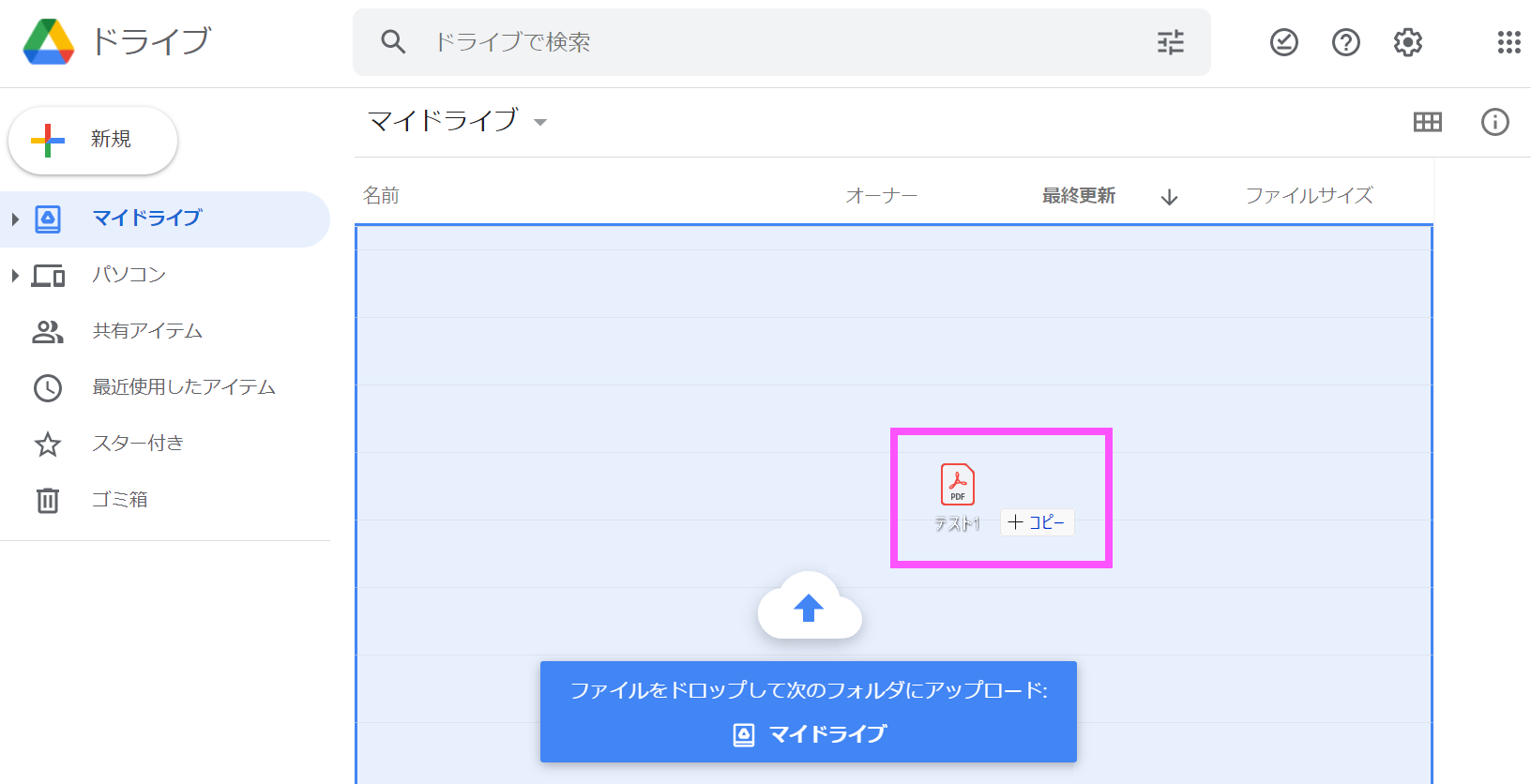
3. PDFの「テスト1」がドライブにコピーされた状態です。
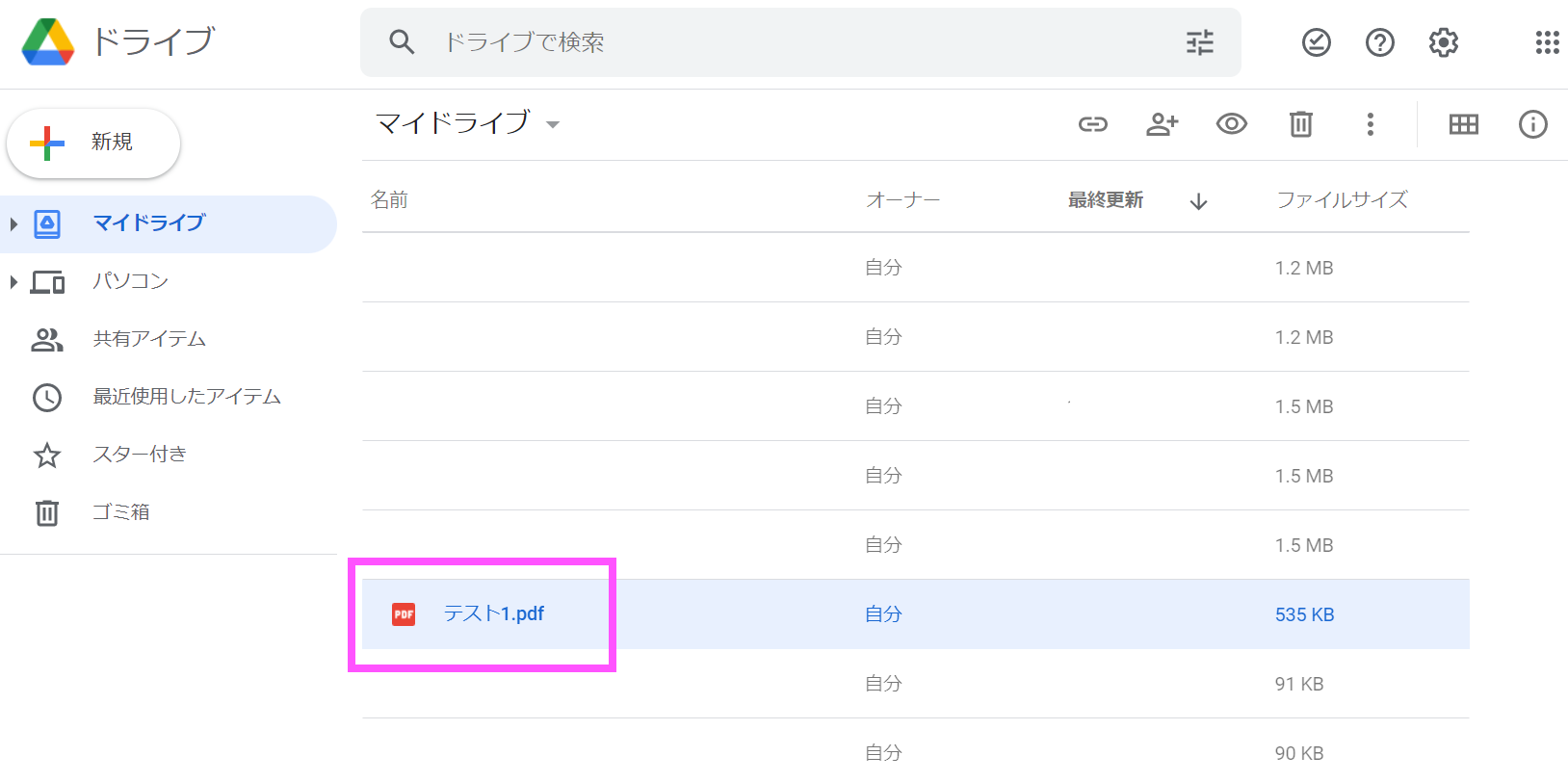
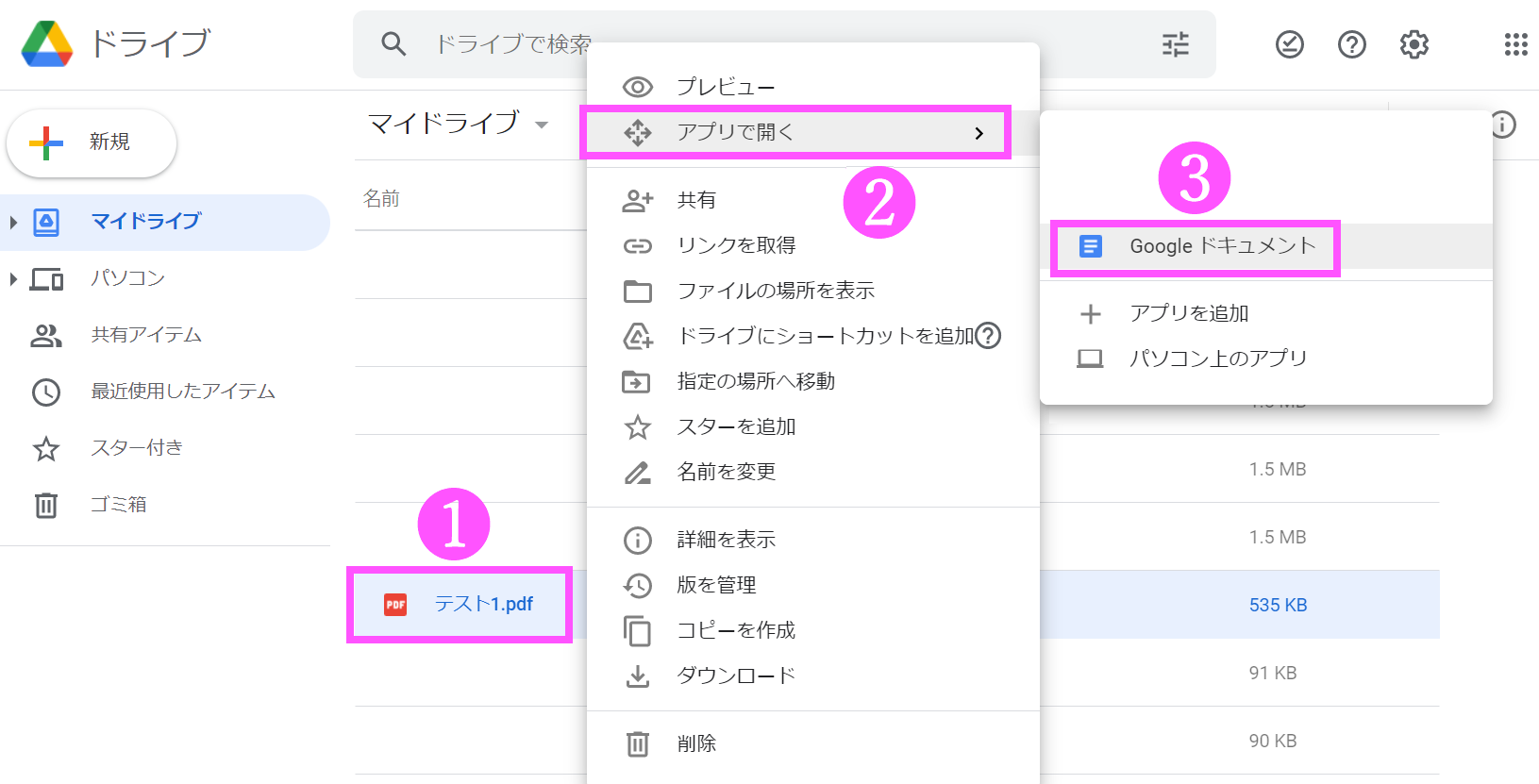
4. 次の❶~❸の手順で進みます。
「テスト1」のファイルを右クリック。【アプリで開く】の項目から【Googleドキュメント】を選択します。
これで文字の読み取りは終了です。
Googleドキュメントが開き、文字情報が読み取られます。以降、実際にGoogleドキュメントで文字を読み取った事例を紹介していきたいと思います。
2. 画像① キャプチャ画像で検証
▼ テスト画像
PCの画面をキャプチャしたものです。

【出典:青空文庫_谷崎潤一郎『細雪』】
このテスト画像を前述の手順で、【ドライブ】にコピーし【Googleドキュメント】で開きます。
■ Googleドキュメントの読み取り結果
Googleドキュメントで先ほどのテスト画像を開いた画面です。
画面上部にテスト画像が、その下に読み取られた文字情報が表示されます。
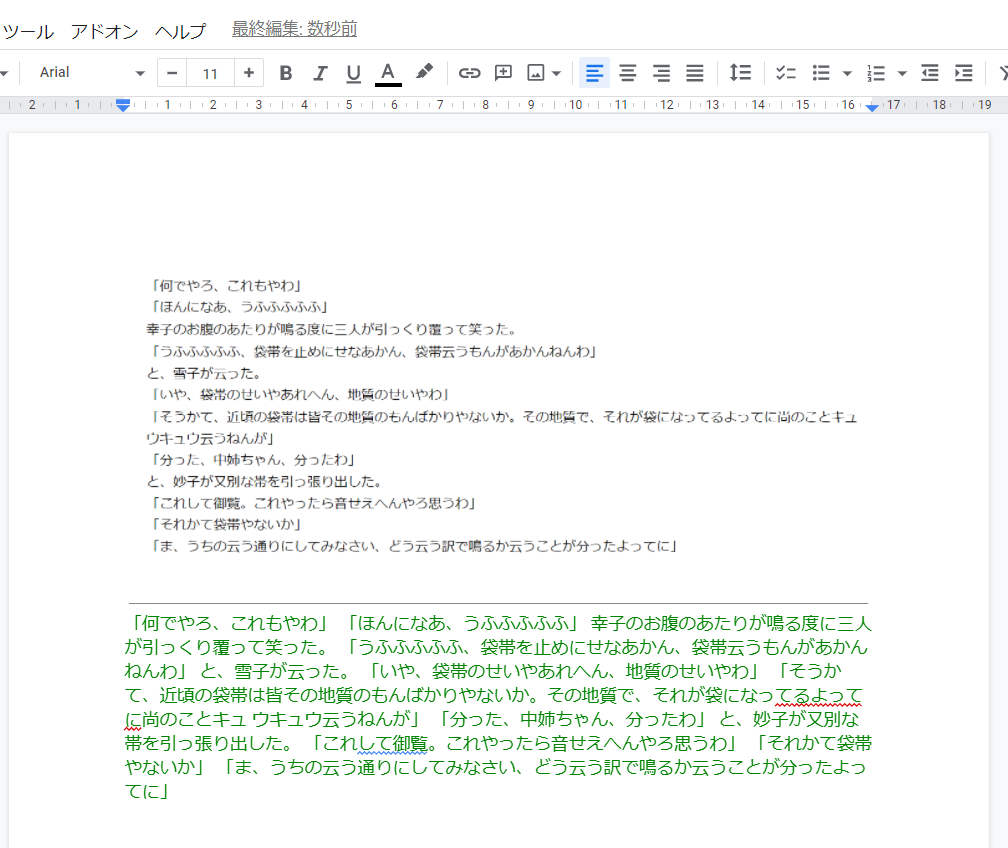
[文字情報部分の拡大です]

改行設定は取られ一文として表示されます。※改行がなくなるかわりに、その部分には空白が入ります。
続いて、この読み取られた文字情報が、元のテスト画像と一致しているかを確認していきます。
■ 読み取り精度の検証
テスト画像の元の文字情報があるので、それとGoogleドキュメントで読み取った文字情報をExcelで比較します。
・Excelで比較した画面です。
左がGoogleドキュメントで抜き出した文字情報、右がテスト画像の文字情報です。
※空白はすべて検索置換で一括削除しています。
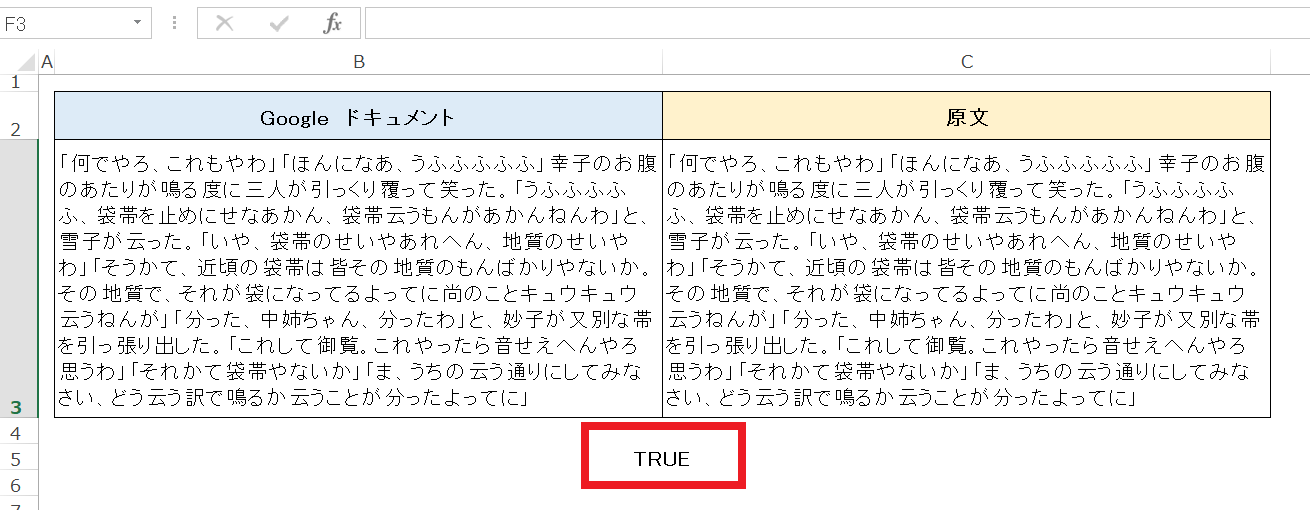
比較結果は「TRUE」と表示されました。完全一致です。読み取られた文字情報は、100%テスト画像と同じものでした。改行設定の代わりに空白が入りますが、文字情報には問題ありません。
テスト画像は、PC画面をキャプチャしたもので文字情報がきれいな状態だったため、読み取り精度が高くなった可能性が考えられます。
次は荒い画像で試してみます。
3. 画像② スマホで撮った画像で検証
▼ テスト画像
スマホで誌面を直接撮ったものです。画像自体がやや傾いていて、明暗も均一ではありません。先ほどのキャプチャ画像に比べればあまり良くない状態です。

【出典:日本エディタースクール出版部_『文字の組方 ルールブック』P.44】
■ Googleドキュメントの読み取り結果
Googleドキュメントで読み取られた文字情報です。

今回は、元の画像の文字情報がなかったので目視で確認します。
以下は文字情報をWordにコピペしたものです。
確認しやすいようにテスト画像の改行位置に近づけました。
※空白は検索置換で一括削除しています。
・Wordの画面

■ 読み取り精度の検証

❶ アスタリスクが、全角から半角に変わっている
❷ 「44-45」のハイフンが抜けている
❸ ❹ ピリオドが句点になっている
❶は、体裁的な間違いです。半角・全角が間違えやすいということを理解しておけば一括で直せるので大した問題ではないと思います。
❸ ❹:元のテスト画像の文章が、句読点のかわりにピリオドとカンマを使用していたので混在したのだと思います。文字が小さいものは、潰れやすく読み取り精度が悪くなります。それさえ理解しておけば、これらも一括置換ですぐに修正できるので大した問題ではありません。
❷は、内容にかかわるので致命的です。これを読み込めなかったのは、元の画像のハイフンが薄すぎたせいかもしれません。
以上のことから、記号・符号類は、特に注意すべき点ということがわかります。ただ、他の文字情報については問題がなかったことから、文字に関しては精度が高いことがわかります。
4. 画像③ スマホで撮った画像で検証
▼ テスト画像
スマホで誌面を直接撮ったものです。画像自体がやや傾いていて、部分的にぼやけています。歪んだ部分もあります。文字の体裁も複数混在しています。
先ほどの画像に比べて、さらに良くない状態です。

【出典:日本エディタースクール出版部_『文字の組方 ルールブック』表紙】
■ Googleドキュメントの読み取り結果

今回も元の画像の文字情報がなかったので目視で確認します。
確認しやすいようにテスト画像の体裁に近づけました。
空白は検索置換で一括削除しています。
・Wordの画面

■ 読み取り精度の検証

❶ ❷ ❹:不要な文字が勝手に入っている
❸:ローマ数字の「Ⅱ」が「Ⅲ」に変わっている
❺:ローマ数字の「Ⅲ」が抜けている
❸ ❺は致命的ですが、文字色や体裁が読み取り精度を悪くさせた原因かもしれません。「Ⅱ」や「Ⅲ」よりも状態のよくない文字はありますが、それらはちゃんと読み取れています。
❶の不要な文字情報について
あくまで仮説ですが、Googleドキュメントで、画像の中で文字のようなものを認識できたけどもそれが何かわからなかったので、あえて一番上に表示させているかもしれません。
ルビ付きの文章を読み込ませたときも、ルビだけが上に表示されました。
逆に考えれば、上に不要な文字が入っていれば、テキストのどこかの文字が抜けているということが推測可能です。
❺の「Ⅲ」の抜けは、Googleドキュメント側が何かあると認識できたが、それが何かわからなかったのであえて上に表示させたということが考えられます。
5. PDF① 文字情報がメインのページで検証
▼ テストしたPDF
文字情報がメインのページです。

【出典:文部科学省_『全国の学校における働き方改革事例集』P.2】
■ Googleドキュメントの読み取り結果

※右下のロゴはムシしています。
■ 読み取り精度の検証
テスト画像の元の文字情報があるので、それとGoogleドキュメントで読み取った文字情報をExcelで比較します。
・Excelで比較した画面です。
左がGoogleドキュメントで抜き出した文字情報、右がテスト画像の文字情報です。
※空白はすべて検索置換で一括削除しています。
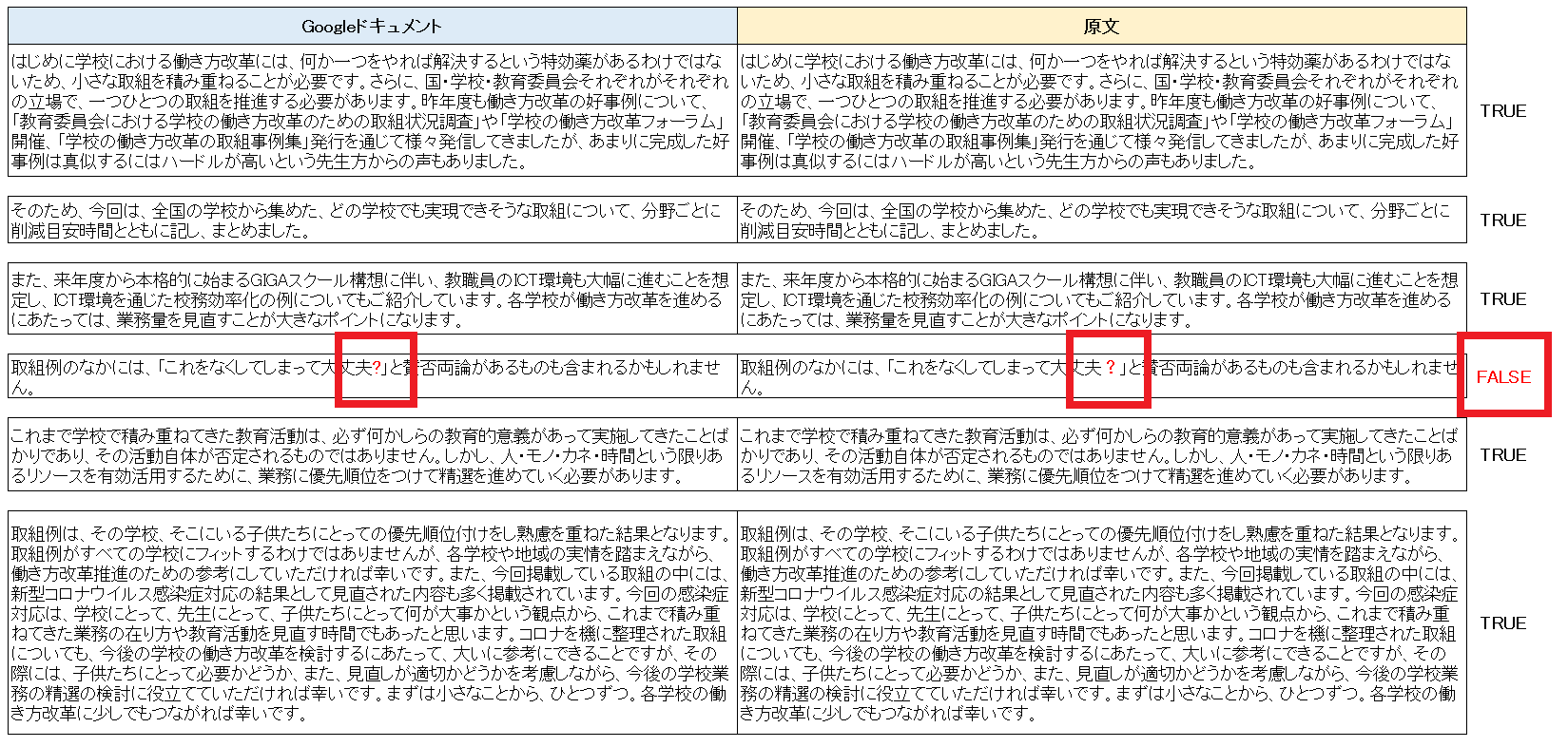
「?」が、全角から半角に変わっている
前述した【3. 画像② スマホで撮った画像】の❶のアスタリスクと同様の現象がおこっています。
記号・符号類は、半角に置き換わるようです。これまでのテストから、記号・符号類に対しては体裁が変更される問題が見られます。
ただ、文字情報の読み取り精度は非常に高いです。ほぼ100%の精度といってもいいぐらいです。
6. PDF② イラスト・表組みありのページで検証
▼ テストしたPDF
イラストや表組を含んだページです。

【出典:文部科学省_『全国の学校における働き方改革事例集』P.12】
■ Googleドキュメントの読み取り結果
■ 読み取り精度の検証
・イラストや表組み部分の拡大です。
■ 元のPDF(イラストや表組み箇所のみ)
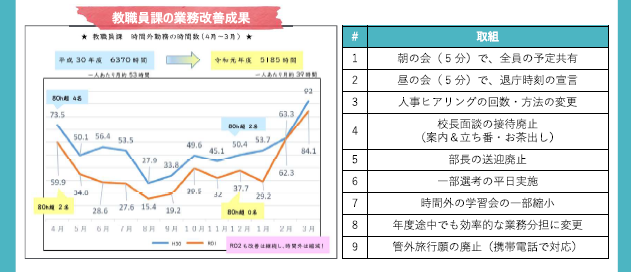
■ Googleドキュメントの読み取り結果(イラストや表組み箇所のみ)

OCRは、誌面を上方向から横軸で認識していくため、イラストや表組みの文字情報がすべてごちゃごちゃになっています。
・表組などは、次のように部分的にトリミングして読み込ませると効果的です。

■ Googleドキュメントの読み取り結果

7. 手書き① 手書き風フォントで検証
▼ 手書き風フォント2種とMS明朝1種です。
文章の内容は、濁点と半濁点、小さいやゆよ、小さいつなど間違えやすそうな文字にしています。

■ Googleドキュメントの読み取り結果

■ 読み取り精度の検証
今回も元の画像の文字情報がなかったので目視で確認します。
確認しやすいように元のテスト画像の改行位置に近づけました。
空白は検索置換で一括削除しています。

❶ 「小さいやゆよ」が通常の大きさになっている
※「小さいつ」と「大きいつ」の判別はOKです
❷ 文の途中で不要な文字(LLL)が入ってる
❷ の原因は不明ですが、❶の文字の大きさは読み取りが難しいのだとわかります。
8. 手書き② 手書きの看板で検証
▼ テストした手書き画像

■ Googleドキュメントの読み取り結果
![]()
■ 読み取り精度の検証
テスト画像の文字は、色も大きさも不揃いです。濁点もほぼ消えかけていますが、すべてちゃんと読み込んでいます。
9. 縦書き文字で検証
▼ テストした文
【7. 手書き①】で使用したMS明朝を縦書きにしたものです。

■ Googleドキュメントの読み取り結果

■ 読み取り精度の検証

❶「小さいやゆよ」が通常の大きさになっている
❷「大きいつ」が「小さいつ」になっている
❷は、横書きでは問題ありませんでしたが、縦書きではうまく読み取れませんでした。
他の文の縦書きも試しましたが、横書きに比べると縦書きは、読み込み精度が少し落ちる印象です。
Googleドキュメントの使用感
現段階では、有料でも無料でも100%の読み込み精度を保証するOCRは存在しません。結局のところOCRの面倒な点は、読み込み後の確認作業です。元の画像やPDFがちゃんと正しく読み取れているかの校正です。
GoogleドキュメントのOCRは、文字情報に関してはかなり高い読み込み精度が見込めます。
この記事内の検証では、文字の誤認識はほぼゼロに近い状態です。半角全角、小書き文字、句読点・ハイフンなどの記号・符号類といった体裁面でおかしくなった箇所はありますが、それらは検索置換で一括処理できるので大した問題ではありません。実務でも十分使えるものです。
OCRは、読み込む画像やPDFの状態に比例して、読み込みの精度も変わってきます。この記事内で紹介したような状態なら同じような結果になってくるはずです。
機会があればご自身の環境で是非試してみてください。きっと役立つはずです。
![表記揺れの意味と表記ルールの考え方[校正の表記統一のルール作りの基本]](https://kousei.club/wp-content/uploads/2022/04/notation-in-proofreading-500x333.jpg)









![促音・拗音・撥音[意味と違い簡単解説]](https://kousei.club/wp-content/uploads/2022/02/assimilated-sound-and-palatalised-sound-and-nasal-sound-500x333.jpg)
![縦書き数字の表記方法[文章内での書き方]](https://kousei.club/wp-content/uploads/2022/07/number-in-vertical-writing-500x333.jpg)
![箇所・個所・か所・カ所の違い[適切な表記と使い分け解説]](https://kousei.club/wp-content/uploads/2024/09/Differences-in-the-notation-of-places-500x333.jpg)

![差し替えと差し換え:どっちの表記が正しい?[意味と違い簡単解説]](https://kousei.club/wp-content/uploads/2022/02/Meaning-of-replacement-and-replace-in-proofreading-500x333.jpg)
![三点リーダーの使い方[意味を理解し正しく使う~例文で学ぶ適切な使用方法~]](https://kousei.club/wp-content/uploads/2023/05/three-point-leader-500x333.jpg)
